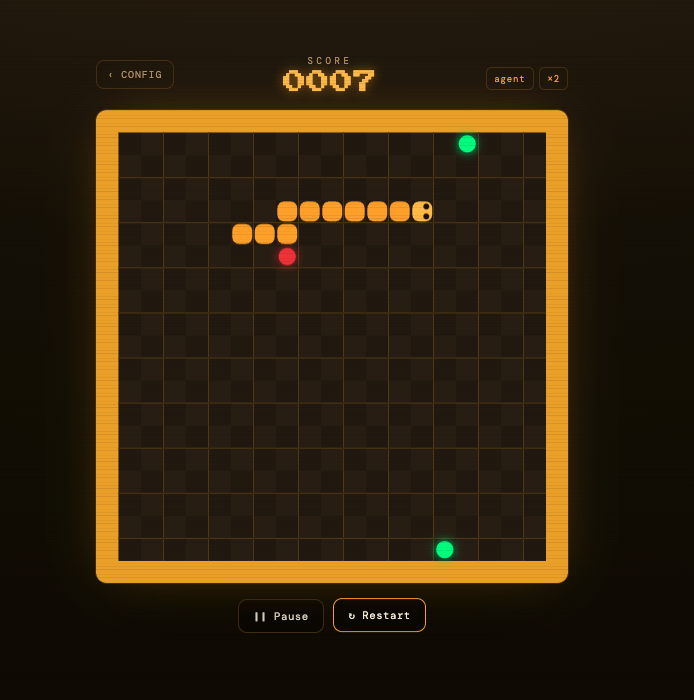
RL agent trained to play Snake from scratch using Q-Learning and Deep Q-Network (DQN) with PyTorch.
Key features
- Tabular Q-Learning: Bellman equation, ε-greedy exploration-exploitation
- Deep Q-Network (DQN): PyTorch neural net with experience replay
- Custom Snake environment: 10×10 grid, green apples grow / red apples shrink
- Configurable episodes and board size — real-time visualization and performance graphs
- Model save/load for training continuation
